Computers and programs, maps and GPS, anything to do with data big or small, as well as my take on the pieces of equipment I use in other hobbies — think bike components, camping gear etc.
Wooo! Did the Superbowl of Chili yesterday with Eric and his neighbor George, and we had a beer-and-chili-fueled blast, if you’ll pardon the pun. No morning run, but that’s fine, Anne and I may do a hike in Jim Thorpe this afternoon.
Meanwhile… My WordPress page (you’re looking at it) uses a theme called Raindrops, which I like a lot of course, but it seems to be a hobby project of some guy in Japan, and there is a persistent error in his code. Specifically, he’s missing a closing anchor tag in the function that creates “featured images,” so that on a page with a featured image, everything after the image is part of the link back to the image’s page. It’s easy enough to find and fix (I did it) but my attempts to contact the author about the error got me nowhere.
Like I said, fixing this error is easy enough, but the Raindrops theme gets updated a lot, and when it does, the file with the corrected code gets overwritten (with a newer version of the buggy code). Every update would find me going in and manually re-doing the fix — it got old.
WordPress themes are built so that one can refer to another, as in a parent theme and a child theme, and the child would inherit from the parent theme all its attributes (layout, behavior etc) except those specifically overridden by the child theme, which can also add functionality etc. This seemed to be ideal for my needs: I could create a child theme, which would only override that one bad function with my corrected version.
My first look at this, several months ago, made me think it wouldn’t work: the original theme’s function coding has to be set up to allow itself to be overridden (each function is tested to see if it does not already exist before being defined), and I could have sworn that my parent theme was not set up like this. I looked again more recently though, and sure enough, everything was good. (Maybe I was mistaken in my first look at the code, or maybe this was added in one of the theme’s many upgrades.)
So I’m good to go, and late last week I sat down and made my child theme, and that all worked out fine. The real moment of truth came this weekend: the parent theme had an upgrade, and the upgrade didn’t break my website. Success!
This is my second post in a series, where I report back on my results from playing with various ways to use routing, in QGIS and related programs. My immediate task is to identify those cycling amenities that are nearest to access points along the Lehigh Towpath. You can read Part 1 (the introduction) here. In this post, I’ll be using the QGIS built-in Network Analysis Library. Follow along after the break…
This is the introductory post for a hopefully four-part series about using QGIS to find the shortest path between two points, not shortest as the crow flies, but following a given network of roads. This is called routing, it’s what’s Google Maps and other mapping software uses, and it relies on graph theory and network analysis to do its job. I’ll talk about the what and the why of this little experiment here; the how (for three different versions of how) will be the subject of subsequent posts.
The reason I’m looking at all this goes back to my interest in cycling tourism, and my attempts to identify cycling-accessible amenities — convenience stores, restaurants, hotels, that sort of thing — along the Lehigh Towpath. My first attempt (you can find it here) basically looked at a region, within a mile (as the crow flies) of one section of the Lehigh River, and searching within that region for the amenities I was interested in. That was an interesting project in its own right, but, as I said in my earlier post, it didn’t really solve the right problem: there are many places within a mile, or even a quarter mile of the river, that are not anywhere near accessible from the towpath: they may be on the wrong side of the river, say, or not near a towpath access point. To be considered accessible, the points of interest would need to be within a mile (or whatever arbitrary distance I end up choosing), by road, of an access point on the towpath.
Data gathered, and almost ready for routing.
I didn’t really have a plan to make this happen yet, but with or without a specific plan, I figured my first order of business was to get the information I would use. That previous analysis used Google Maps, but I felt that their data was a bit encumbered (in terms of my rights to it), and it seemed that Google didn’t play as well as I’d like with QGIS anyway, so I decided to use the data available through Open Streetmap, for both the road network and the set of amenities. (I already had a collection of the towpath access point locations left over from a previous experiment.) I got those sets of data, and massaged them so that I only had the parts that fell within a mile of the bike paths in the Lehigh Valley. This gave me the data seen to the right, where the aqua lines are the road network, the red lines are bike trails (the towpath, plus the Palmer Bike Path), the red stars are trail access points, and the orange dots are the amenities (restaurants, fast food etc).
(One note about the road network: You probably can’t see it at this resolution, but I made a point of excluding roads that are not practical/legal/safe for cycling, like US-22, I-78 and a few others. There are also a number of places, like the New Street and Hill-to-Hill Bridges, where roads or the trail are connected via stairways to the bridges above; after our own struggles, a few years ago, with stairs and fully loaded touring bikes at the Ben Franklin Bridge, I decided to also exclude stairways from my network.)
So that gets us the data, what about the analysis? My first thoughts were to see if I could find all the points on the road network that were a mile away from an access point, then connect the dots to define a region, and then find all the amenities within that region. My second thoughts were that this approach would put me back in the same situation as my first attempt, since I could easily find roads that were not reachable within that region, such as bridges. (Bridges became my nemesis for a while.) I eventually decided that my best strategy would be to find the shortest route between each access point and each amenity, and select from the amenities based on the lengths of the routes I found.
To perform the actual routing analysis, I have three options:
In terms of a learning curve, I have some experience with networks in GRASS, and I feel at least a little comfortable with Python (and copy-paste, with scripts I find online), so pgRouting will probably be the most difficult for me to pick up. Meanwhile, the Network Analysis library can use the data I already have, but Open Streetmap deals with road networks in a way that’s not directly compatible with either GRASS or pgRouting — their topological models are different, but that’s an issue for a future post. I would have to either re-import the road network to get it to work with pgRouting, or further process the one I have for GRASS.
Each one of these approaches will be the subject of its own post. Given that the Python approach is not the hardest, and my data is already in the form I’d need, I am going to try my hand with the Network Analysis library first. Stay tuned for Part 2, whenever…
I still have no idea what’s going wrong with scanning photographs of QR codes (other than, say, generic image quality issues inherent in the process), but I’ve sort of abandoned the whole QR thing. The obsession ran its course, and there was also this:
We went out last weekend with John and Donna, and also a friend of ours who is a programmer. She asked me about my recent projects and I said I was intrigued with QR codes, and she said something to the effect of “Oh, aren’t they a bit passé?”
What?!?? I asked John, and he also felt that they were a technology that seemed promising maybe a few years ago, but eventually the buzz faded as they were seen to be superfluous — users could write information (or capture the info another way, like near field communication) as easily as they could use a phone to scan and capture it from a QR code.
I went home and did a little Googling and — except in the marketroid world where it definitely seemed passé — the situation wasn’t nearly as dire as the picture my friends painted, but what I saw online did make me reevaluate their usefulness, to take stock as it were, and my interest, already waning, disappeared.
I’m not sure why I did this exactly, but the other day I decided to download a QR code generator onto my phone. I have no real need, but it looked like a fun thing to play with, so I made a few codes (my contact info, “Hello World!” etc), then I thought it would be pretty cool to read and write them from the laptop, so I downloaded a program called qrencode to write them, and one called zbar to read them, and I had a bunch of geeky fun using all my new toys.
Then I got the idea: what if I could take a picture of a QR code, with datestamp and GPS metadata added? I could then extract the QR data, and the time and place it was gathered, like maybe something an inventory program would use. I downloaded another program called exiftools, and found how to get the date/time and location from the photos, but the final step, extracting the QR data from the photo of the QR code image, was a failure. I have no idea why yet.
We saw it the other day, basically as soon as it was out in a nearby theater. We happened to go on a weekday matinée, which is what we usually do, but unlike other matinées the place was packed — it looks like we weren’t the only ones who wanted to see this movie. And it did not disappoint: this was one of the few times where the movie audience applauded at the end. My advice: go see it. (You’re welcome.)
The story follows three black women who work as “human computers” for NASA in the early 1960’s. “Computer” was actually what they were called; it was a real but low-status job for low-status (female, black) math whizzes in the days before electronic computers, and there were rooms full of them, like steno pools, at NASA. This being Virginia in 1961, our three heroines were relegated even further into the segregated “colored computers” pool. So with the budding Civil Rights movement as backdrop — and this movie excelled at backdrops, with an awesome period score and loads of what looked at least like archival footage — these women broke through racist and misogynist barriers, and got John Glenn into orbit.
And then, just as electronic computers started to threaten their human computing jobs, they figured out how to be the ones to do the necessary work of programming those computers. (It wasn’t in the movie, but programming back then — difficult, exacting, requiring daily brilliance just like now — was another low-status job for “girls.”)
One thing caught me though, not in the story itself but in how the movie was put together. I remember reading once about how some movies were subjected to audience polling, and changes based on that polling, before final release — I wasn’t quite aghast, but it kind of irked me that this was done, and I started seeing what I thought was poll-driven editing everywhere in the movies I watched, and I thought I spotted it here.
There were two (three) parallel stories going on: one (two) involving lowly employee showing them how it’s done, and the other showing the futuristic but inert IBM that NASA purchased being brought to life. The stories were finally brought together, mostly by the juxtaposition of the two “TRIUMPH! THE END” endings, but at one point there seemed to be an aborted attempt at a connection…
The top NASA engineers are trying to figure out some orbital mechanics and realize that they need a different mathematical approach, and Katherine Johnson says “Euler’s Method!” Eureka! But then that’s it: other than a scene where she reads up on the method in an old text, there’s no follow-up. The thing is though, Euler’s method is a numerical method, made up of many simple calculations instead of a few sophisticated ones, and it’s prohibitively impractical as a tool without the electronic computer. I can almost see the missing scenes, where Katherine’s superiors despair of getting the answer in time because there’s just too many calculations, just as Dorothy Vaughan got that old IBM up and running in time to save the day — oh what might have been! …but that’s getting nitpicky, me dreaming up extra scenes, just because I wanted the movie to go on and on.
This movie was morally affirming — righteous even, and patriotic — without being preachy, pro-science without being hokey, and overall a pleasure to watch. Go see it, and see if you don’t applaud too at the end.
“I woke the President to tell him we were under attack by the Russians!
Do you know how stupid that makes me look?!!”
— War Games
I moderate comments here: if you’ve never had a comment approved, all your comments go into a holding tank until I either approve or trash them, though once your first comment has been approved your subsequent comments are all automatically approved. It usually doesn’t matter much, since I don’t get many legitimate comments and have only one commenter, but that’s the way I like it because it blocks comment spam.
The other thing about comments is that I get an email every time one is posted. This is on my “extra” email account, which doesn’t get much use, especially after I unsubscribed from a mailing list I was on. Then this afternoon my phone dinged a few times, and when I looked I had 22 messages, all from this site and saying I had comments in moderation…
My site hadn’t gone viral, it was all just robo-spam: gibberish with a couple of websites thrown in, that kind of thing. I dealt with that set of comments by trashing them, and then a few hours later I got more, which I also dealt with. I noticed, though, that despite different names and email addresses, they were all coming from two internet addresses. I blacklisted those addresses, so now the comments go straight to trash, and I don’t get email notifications.
I just checked the comment trash here, and it had a ton of spam comments. I guess I’ll have to check and empty the trash every so often until this entity gets tired of sending them, but as far as I’m concerned it’s problem solved.
By the way, the offending internet addresses are assigned to a Russian ISP.
UPDATE: The spam continued for about 12 more hours then stopped.
I had a problem to solve at work last year, basically to make a cone out of bent tubes, to form a cone-shaped “throat opening” in a wall made of vertical tubes. The task needed a bit of iterative trial-and-error to solve for each tube, which quickly becomes tedious when there are maybe a dozen tubes that have to be looked at — half a day’s work — for any given throat configuration, and there were a bunch of configurations we wanted to explore.
You can read about it here, but after that first day of tedium I decided to see if I could automate the process. I wrote a short C program, including set of vector functions and a root-finding function (using the Bisection Algorithm, which is supposedly slow but fast enough for my purpose — more important to me was that it’s pretty robust, and guaranteed to work in my situation), to find the necessary workpoints and design requirements for an individual tube in the cone. I then wrote another program to generate the input data for each individual tube, based on the tube, wall and cone parameters. I could give the “cone_maker” program the tube OD, bend radius and minimum allowed straight between bends (tube parameters), the number of tubes and tube spacing on the wall (wall parameters), and the cone inner and outer diameter (cone parameters), and pipe the results through my original “throat tube calculator” program, to get the data I needed. The programming took about two days, maybe a total of four actual hours of programming time, and it ran — flawlessly — in seconds.
Unfortunately, to use the program I had to go through a whole rigmarole, running it on my SDF free shell account and accessing it on my phone via ssh, since we had no real resources for running or compiling programs at work. The process was faster, but still very tedious — you try typing dozens of numbers into and reading the results off a tiny phone screen — but it got the job done.
The program did what it needed to, and it looked like I wouldn’t ever need to use it anymore, but I started thinking about program improvements to make the tube design process easier. You can read about these changes here, but what I decided to do was add new output options to the throat tube bend calculator: one option that produces AutoCAD commands to draw the “skeleton” of the tubes, and another to create a lisp file (AutoCAD uses lisp as its scripting language) to make a 3D model of the cone tubes. This took more work than it needed to because checking the results had to be done at work, while coding had to be done at home, but within days I had the program output running smoothly. I then armored the programs and turned them into a CGI script, and made a web page to access it.
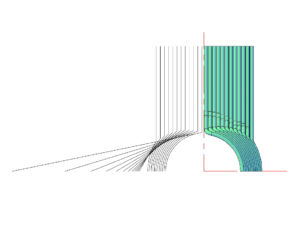
Throat Calculator Outputs in AutoCAD
Here’s the calculator web page, and the results can be seen to the left. I had absolutely no use for the calculator anymore, but it sure was fun to play with.
Fast forward to now, and I thought it would be fun to play with again — unfortunately, I don’t have AutoCAD at home, and am not likely to get it anytime soon, but I do have a program called FreeCAD. Now FreeCAD does not use the same things AutoCAD does, but it does have a built-in scripting language: Python.
Python has been on my radar for a while, and with my recent QGIS forays (QGIS also uses Python as a scripting language) I’ve been motivated to learn a bit more about it. Then I happened to see my version of FreeCAD get auto-updated the other day, and thought it would be nice to play with, and maybe pick up on some Python on the way….
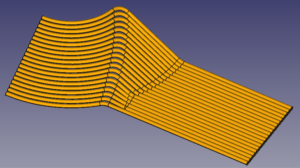
Python-generated quadrant of the cone.
So I rewrote my cone maker & tube calculator programs in Python script. Much (but not all) of the vector stuff is available in a library, and so are root-finding algorithms — just for laughs I used Brent’s Algorithm, a faster version of Bisection — and Python code is naturally more compact-looking than C, so the final program looked really nice, and much shorter than my original C programs. In terms of running, there seemed to be a lag at first (probably importing all the libraries I called for), but the output just about spit itself out.
Once I got the program to produce correct numerical output, I moved it into FreeCAD and started figuring out how to create the tubes. This took a bit of research, and a bit of trial and error, but the whole learning process took less than a day and then it was running beautifully — you can see the results to the right, and the full throat below.
So what else have I been up to lately? I decided to look a bit more closely at QGIS, the open-source GIS program, and so I found a group of online courses on using it. They’re free, and you kind of get what you pay for here, but they’ve been an eye-opener into QGIS and its capabilities — it’s a much more powerful program than I realized, and with the ability to run R, GRASS and Python scripts, as well as automating tasks (and linking them together like unix pipelines), it’s got almost limitless expandability. I’m working through the third course (of five) right now, and when I’m done with these I may start looking into possibly going further.
I love my Garmin, but the map it came with was horrible, so I replaced it with one from OpenStreetMap. (This is not news; I got the map years ago.) The process is tedious but pretty simple: there are sites you go to, and you pick what parts of the world you want a map of, then they do some data processing and email you to let you know when you can download your map file. The files are huge, like 3-4 GB for the one I got for North America, and they take a while to process and even longer to download. But once you have the file, you just put it on a micro-SD card, stick it in your GPS, and voilà — a much better map!
Maybe it was the choice of map file I made back then, or maybe OpenStreetMap back then was less complete, but my map didn’t have many offroad trails. I didn’t feel the lack too sorely, since on most of my offroad rides I already know where I am, but after the last big ride — when I had become a bit lost — I looked at our path on the latest OpenStreetMap cycling map, and I saw all the trails through the strip mines — singletrack, jeep road and all. Boy, wouldn’t that have been nice to have on the ride! I also noticed that all the trails on Broad Mountain are now on the map, including the “secret singletrack.” I’ve done a couple of (road) rides recently, where I mapped out a course online and then downloaded it to the Garmin and used its routing features, “turn left onto Main Street in 100 yards” etc, to follow my course, and I thought that it would be a great thing to try routing with an offroad ride. The only thing I’d need would be routable trail maps…
My understanding of the Garmin 810 is that multiple maps can be installed and enabled, and I’d been reading up on how to make the Garmin maps. (For years I thought it would be a cool project to make small custom maps of local trail systems, either standalone or as add-ons to a base map, but other than some re-purposing of GPX tracks I never really pursued it.) I didn’t feel like going through the process of downloading another huge (updated) map of North America from that map service again, but generating much smaller add-on maps myself, using OpenStreetMap data and the same software the original map service used, seemed to be fairly straightforward, and I could make a smaller updated file to add to my base map.
So that’s exactly what I did: I downloaded the data for a region around Jim Thorpe and saved it on my machine, then ran a Java program called “mkgmap” to create the map file. Installed it on my Garmin, and voilà — the trails were there! I then created a course online, following some Broad Mountain trails I know well, and arranged to go riding with Rich B.
Results were mixed. Our ride was great, but the downloaded route beeped an error message while loading and would not do any routing, though it would show the route on the map, and would indicate if we went off course. I got home and found that I’d compiled the map without routing capabilities, so I recompiled and reloaded my new map; it still awaits testing since I don’t get up to Jim Thorpe in a very regular basis.
Meantime, I thought I’d make a similar map for the trails at Lake Nockamixon, since I did have immediate plans to ride there. I drew up a course to follow (which worked fine), and compiled a map of the Nockamixon area, but this new map would not display on, or even be recognized by, my GPS. I tried making a few other maps, but the only one that ever worked was the original Jim Thorpe one, and I have no idea why. I eventually got so frustrated that I went out and bought a new micro-SD card, and re-downloaded the map of North America, a process that took about six hours (though I wasn’t actually present for most of it).
My next offroad ride will include a test of the trail routing capability of my new map. It better work.
(Just as an aside: my resting heart rate this morning was 49 BPM.)