Computers and programs, maps and GPS, anything to do with data big or small, as well as my take on the pieces of equipment I use in other hobbies — think bike components, camping gear etc.
A computer update: the file selection dialog boxes on my machine, as well as quite a few programs, rely on GTK+3 widgets, but my desktop is really MATE (using GTK+2), and the generic theme that the GTK+3 stuff gets rendered in was just plain ugly, so I added an upgrade to the Cinnamon desktop, and have been playing with that for a bit. My thoughts so far:
Cinnamon seems faster, and seems to also use less computing power.
It (Cinnamon) seems less complete, and more buggy, than MATE.
It has some clean looks, but it is really plain, and all my favorite little pieces of eye candy are gone.
I tried going back to the MATE desktop, but I found that even though I enjoyed having my toys back, the ugly GTK+3 programs really were too much, and so I’m trying to get used to my new plain-Jane desktop. (I should look into installing a MATE theme that works for both GTK+2 and 3. Then I could go home again.)
One motivation for changing desktops was that I was planning to use Eclipse as an IDE for Python, which meant that I had to start using Eclipse, one of the ugly programs under MATE. I also upgraded to the latest Eclipse, and installed Java 8, the latest Java runtime environment, and added the PyDev IDE plugin. OK, all of that went well, though I did things in a slightly nonstandard fashion, and I now have an up-to-date Eclipse IDE with Python, as well as C/C++ and Javascript installed.
But in the meantime… The next time I fired up the Java Open Street Map editor (after installing the new Java), JOSM just puked a bunch of error messages. No idea what went wrong, but I was launching it with the old Java Runtime Environment, and I thought that maybe there was an interference with the new environment I installed. So, I tried launching it with the new JRE, and it came up just fine, along with a message that, at long last, it too had been upgraded to the new Java 8, purely by coincidence but at the same time as my own fiddling.
Anyway, all is well again, if slightly dull, in my computer land.
I took the bike up to Sals for its maiden voyage, and I managed to catch a tree with the left handlebar — the handlebars are much wider than the ones on my Turner, or any of my other bikes — on a downhill no less, just after the 3 B’s climb, and it dumped me at speed into the rocks. I landed on my right knee, hard enough to see stars, and to literally bounce across the trail and roll down the hill. It took me 10 minutes to even get up, I was convinced I’d broken something, and I had to walk most of the way home. I spent most of the afternoon and evening with ice on my knee, and I will be doing the same today.
Other than that it was an OK ride, not awesome but OK. The Santa Cruz rides quite differently than the Turner did, and there will be some things I will just have to get used to, and a few things I’ll need to do — suspension adjustments, seat height, possibly change the handlebar length (shorter) and the stem length (longer) — to dial in the ride. I would like for the bike to be a bit more responsive in turns, but that may come with time and those adjustments.
There are three pieces of new technology, new to me anyway, on this new bike: tubeless tires, an adjustable seatpost, and 1×11 gearing. The tires are probably an improvement, but one — the absence of flats — that I might not really notice, and the seatpost is a cool gimmick so far, but it’ll be a while before it’s really incorporated into my riding; the new gearing is a bit more problematic. I went from 17 effective gears on the Turner’s 3X9 to just 11 here, and it seems like I have less of a high end, and less of a low end, as well as a less fine-grained set of gear choices. This may be the hardest thing to get used to, but there is apparently no going back: triple chainrings, and even doubles, are being phased out on mountain bikes, this is a weight savings for what could be a bigger and heavier bike, and I think the Santa Cruz has a lower bottom bracket, so a smaller, single chainring helps with ground clearance.
Anyway, the bike seemed to perform well, especially on downhills, though the big crash wasn’t my only one yesterday, and though it seemed both twitchy (the short stem) and hard to turn (the long wheelbase) it did well enough at Sals. Unfortunately, it’ll be a while before I get to ride it again, and even worse, I’m going to have to bail on the Wilderness 101 this weekend.
That’s right, no W101. We saw Renee last night and I had to give her the bad news. I felt like such a disappointment, but I won’t be walking much, much less riding, in the next week, and even if I could ride, my knee could never handle 100 miles the way it feels now. Timing is everything.
I’ve had trouble recently with using my email here at donkelly.net: some — not all, but some — networks wouldn’t communicate with mine, emails couldn’t be exchanged, and looking into why that was so, at say, SDF.org I found that they couldn’t even resolve my domain. The domain always resolved on my home computer though, so some DNS was working somehow.
But my laptop generally uses the DNS server on whatever wifi it’s connected to, and now, connecting here on Rainbow Lake, whatever DNS server they use wouldn’t resolve my domain — which I took to mean uh oh, there really is a problem with my setup and not just at SDF or whatever.
I checked my DNS info using third party websites and found that here were some major discrepancies — there were four nameservers listed rather than two, and two of them didn’t work. Turns out the original ones had been retired (by my service provider) but my system hadn’t been updated, and the broken servers were the retired originals, which were the only ones listed in my site’s configuration — I have no idea where/how the correct nameservers got listed. I went in and removed the bad servers, added the good ones to my configuration, gave it a few hours, and now even the formerly broken emails seem to work.
I could have, and should have, done something about this months ago.
I’ve been thinking a lot about the economic impact of the towpath lately, and have been looking to the Great Allegheny Passage as a model, where many food and lodging places have popped up to cater to the cycle touring crowd. I know that the D&L Corridor people are also looking at various businesses and how the towpaths might impact them, but I believe that they are looking at it from a county-wide perspective, when they should probably really be looking at impact within a few blocks of the path, and or at least within about a mile of the river — would you decide to take a fully loaded touring bike miles out of your way, and probably up some hill to get away from the river, just for say, lunch, if you didn’t absolutely have to? So, that got me thinking about the question: what restaurants, hotels, bike shops, and other amenities are actually within a mile of the relevant sections of the Delaware and Lehigh Rivers?
(This was a good first approximation, but it’s surely a naive way of looking at the problem, since there are many places within a mile of the river as the crow flies, that are not actually within a mile, or maybe even many miles, of anyplace accessible from the towpath — and places that will see towpath business will need to be located within a matter of blocks, not miles, from towpath access points. But I realized all that later as I thought more about the overall situation, and my first analysis of towpath business prospects was what I worked on first.)
The way I looked at it, my original problem broke down into two parts. First, what is the region within one mile (or whatever distance) from the river, and second, what are the amenities within that region? The first part was fairly straightforward, but the second, which looked like it would involve some kind of Google Maps search — and eventually it did — turned out to be more complicated than I thought…
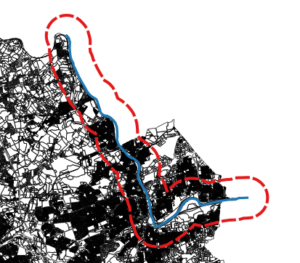
Nifty QGIS: Five minutes of work to get the buffer zone.
I used QGIS to deal with the first part. I took as my reference some Pennsylvania aerial photos, plus a property map of Lehigh County, and created a new line vector (in a projection that uses feet as a unit of measure), following what looked like the middle of the Lehigh River from about Laurys Station to just past Bethlehem, and then I used the “Create Buffer” geoprocessing tool to create a vector polygon buffer region around that section of river, whose distance from my line vector was 5280 feet, in other words, one mile. That part worked great, but what to do with my buffer region?
My first thought was to take the buffer vector and export it to a KML file, import that KML file into a custom Google Map (using Google’s “My Maps” personal map creation/editing feature), and then “do something” with it. That all worked great as well, up until the “do something” part — the KML file, and the personal map, were not much use when it came to customizing a map search.
I did find online, however, that there were some things you could do with polygonal regions, and testing locations (such as the ones returned from search results) to see if they fell within those regions, using the Google Maps API. This added two new steps: first I had to re-export my buffer region, this time as a GeoJSON file because that was what the API would accept, and I also had to sign up for an API key from Google Maps. Both of these were also straightforward and easy to do.
The final step was to put it all together: make a web page, and (with some javascript), load and draw the GeoJSON file, run a search (for restaurants, in my experimental code), and then find and display results that fell within my region. Code code code, give it a try… nothing. I was able to load the file and see my region, but no place results would be displayed.
Turns out, there is more than one Polygon type in the API, and the one created by loading a GeoJSON file is different than the one you can test locations against; I would have to convert my polygon from one form to another. (This seemed to me a bit much, especially since I thought I should have been able to load the original KML file and it would “just work.” After all, isn’t KML a Google thing, and kind of a standard?) No matter, the conversion process from one polygon to the other looked as straightforward as every other step so far, so I just added it to the end of the task chain. Code code code, give it a try… nothing, and here is where it started to get really frustrating.
I couldn’t for the life of me figure out what was going wrong, it looked like I did things exactly the way I was supposed to but my new, converted polygon could not be made, and it looked like the original polygon actually was empty, even though it was drawn on screen. I eventually used a callback routine from the GeoJSON loading function to get the polygon coordinates, and for some reason that worked.
That gave me my clue: the “some reason” was that the callback was not executed until after the file was done loading, so the conversion routine had something — a non-empty original polygon — to work with, while in my original code the rest of the script wouldn’t wait for the file to finish loading before continuing, so there really was nothing to work with yet when I tried to do the conversion. That took three paragraphs to write, but more than a day to work out…
I didn’t really like my solution: if you’re forced to use callbacks like that, you end up going down the rabbit hole, callback after callback after callback, just to get some semblance of sequential execution. (Meantime, I found that some methods did not suffer from these kinds of problems, they seemed to wait for the data to load before trying to work on it. Strangely enough, all the simple API examples I found at Google used these methods instead of the one I needed.) Eventually I set up a wrapper function to hide the messy details and just get me my goddamned polygon from the goddamned GeoJSON file.
Anyway, here is my demo map:
UPDATE (7/26/2018): This map will stop working after July 30th, because the “radar search” function (see script below) has been deprecated by Google Maps. I may take some time to update the script — which I’ll mark with another update — but then again I may not, because this is a low-usefulness, low-visibility, low-priority thing for me, and also because fuck Google.
And here’s my script. Most of this is based on Google Maps API examples, but the function getBuffer() loads the data, and createBufferPolygon() is the wrapper that creates the polygon object:
var myNewMap; // the google map
var myPlaceService; // object for google places api
var myBufferPoly; // the polygon that holds the buffer region
var myInfoWindow; // info window for the selected place
// the callback function from loading the API, where everything actually happens
function initMap() {
myNewMap = new google.maps.Map(document.getElementById('map'), {
center: {lat: 40.672628, lng: -75.422778 },
mapTypeId: google.maps.MapTypeId.TERRAIN,
zoom: 11
});
var bikeLayer = new google.maps.BicyclingLayer();
bikeLayer.setMap(myNewMap);
myBufferPoly = createBufferPolygon(
'lbuf2.geojson',
'lehigh',
myNewMap,
true,
'green'
);
myPlaceService = new google.maps.places.PlacesService(myNewMap);
myInfoWindow = new google.maps.InfoWindow();
getSearch();
}
// this is the wrapper function, which calls the function that loads the GeoJSON file
// after creating the polygon to hold the buffer region
function createBufferPolygon(url, featureName, map, isVisible, polyFillColor) {
var bufPoly = new google.maps.Polygon({
map: map,
clickable: false,
visible: isVisible,
fillColor: polyFillColor
});
getBuffer(url, featureName, bufPoly);
return bufPoly;
}
// this function loads a GeoJSON file containing a named polygon
// then adds it to the given polygon object
function getBuffer(url, featureName, poly) {
var bufGeom;
var bufferData = new google.maps.Data();
bufferData.loadGeoJson(
url,
{idPropertyName: 'name'},
function(featarr) {
bufGeom = bufferData.getFeatureById(featureName).getGeometry();
poly.setPaths(bufGeom.getAt(0).getArray());
});
}
// finds all restaurants within 15km of a certain location
function getSearch() {
var request = {
location: {lat: 40.703117, lng: -75.416561 },
radius: 15000,
keyword: 'restaurant'
};
myPlaceService.radarSearch(request, displayResults);
}
// displays search results that fall within the buffer region
function displayResults(searchResults, searchStatus) {
if (searchStatus !== google.maps.places.PlacesServiceStatus.OK) {
console.error("getSearch error: " + searchStatus);
return;
}
for (var i=0, result; result=searchResults[i]; ++i) {
if (google.maps.geometry.poly.containsLocation(
result.geometry.location, myBufferPoly)) {
addMarker(result);
}
}
}
// adds marker for selected places
function addMarker(place) {
var marker = new google.maps.Marker({
map: myNewMap,
position: place.geometry.location,
icon: {
url: 'http://maps.gstatic.com/mapfiles/circle.png',
anchor: new google.maps.Point(10, 10),
scaledSize: new google.maps.Size(10, 17)
}
});
google.maps.event.addListener(marker, 'click', function() {
myPlaceService.getDetails(place, function(result, status) {
if (status !== google.maps.places.PlacesServiceStatus.OK) {
console.error(status);
return;
}
myInfoWindow.setContent(result.name);
myInfoWindow.open(map, marker);
});
});
}
That’s a lot of work for something that solves the wrong problem! My next look at this will likely just involve finding the access points, and doing Google searches near each one — soooo much less elegant…
I use Linux Mint, which is based on Ubuntu, specifically a less-than-current version of Ubuntu for whatever the current version of Mint is. The Ubuntu distribution is in its turn made up of software packages that do not get major upgrades (except for, say, security fixes) within any specific version, so by the time I get the “latest” Mint, the actual programs and applications are actually months, if not years out of date. This drives me nuts sometimes, especially when I run across a bug, Google it and find that it had been fixed last year but it’s not available to me, at least through the official Mint channels.
In situations like that, you can do things the old-fashioned way (download the source and build it yourself) or you could find a pre-packaged installer file with the latest version, but these now knock you off any available “upgrade path” for that application. The better way is to find another channel from which to receive the software packages, one that is more up-to-date than the official ones.
(By the way, these channels are called “repositories,” and they are just online sources for the software packages. The packages themselves are compressed bundles of files that contain the software, along with information about what other software, specifically what versions of other software, the package needs, which are called its dependencies. The “package management system” reads these files, figures out what else needs upgrading — or if it can be upgraded — and takes care of upgrading the software and its dependencies from the lists kept in the repositories that it knows about.)
It’s somewhat frowned upon, since “unofficial” repositories may be malware, or even just poorly made, but I’ve added a few of them to my lists of software sources. I’ve done it to get the latest available Libre Office, and also the latest version of R, for example, and yesterday I decided to do the same with my GIS software, using what is supposed to be a very useful, up-to-the-minute repository.
Well, it was a little more complicated than that, since the version of GRASS in the repository is 7.0, and the version of QGIS was 2.8, and it turns out that the GRASS plug-in for QGIS 2.8 was broken by the newest versions of GRASS, which is bad because a good portion of QGIS’s advanced functionality comes from its ability to work with GRASS. I’d upgraded myself right out of a useful program… I did a bit of Googling, and found that later versions of QGIS had the problem resolved — wait, later versions?
It turns out that this cutting edge repository was also not the latest, and I had to get the latest directly from a repository maintained by the makers of QGIS. I feel like I built myself a house of cards, QGIS repository on top of unofficial repository on top of Mint, but at least I now have the software I want.
I’m not even sure why I turned it on, but for some reason, some time in the past, I did turn on the Compiz effect called Freely Transformable Windows. I probably clicked on it randomly to see if anything dramatic happened, didn’t notice any changes and moved on, but if you look at the description it sounds pretty cool: you can rotate (in 3d) or tilt or scale any window, including its contents. If you look closer at the description though, you’ll also see that once the window has been “freely transformed,” you can no longer “interact normally” with it, meaning you can’t use it at all, or even close it normally — it’s like it’s locked up, with the window crooked.
So like I said, I forgot about selecting it, and had no idea what it did in the first place. Unfortunately, it has a bunch of Control-Shift-Letter commands to initiate the effect, which override other uses of those same keyboard shortcuts, so I would be in Firefox say, press Control-Shift-A for the add-ons page, and instead of getting what I want the window would go crooked and lock up. As far as I could tell, it was some weird and serious bug.
Well tonight I just happened to do a little Googling, and found the info that reminded me of what I did. I turned off the effect, and all is right with the world.
I turned it off, as well as all the RSS feed screenlets I had all over my desktop. (I kept the clock.) Those RSS screenlets turned to be a distraction and an annoyance, and luckily nothing worse, but I’m pretty sure that Conky made my system unstable: whenever I had it running more than a day or so, I started getting weird crashes in other programs. Turned it off, crashes (at least,thosecrashes) went away.
I’m keeping most of my Compiz eye candy, but it turns out I actually prefer a cleaner desktop…
I’m not sure why or even how this happened, but ever since I upgraded to Mint my web server had been dealing with PHP in a very unsatisfactory manner: as long as the PHP file was in the main website area (/var/www/html) it worked fine, but I usually keep my web stuff in my own “user directory,” and in that directory any actual PHP was just totally ignored when the file was served up.
This, for security purposes, is basically the default behavior, and there is supposedly an easy way to change the behavior, which involves minor changes to the configuration files. But, when I made those changes to the configuration there was no corresponding change in behavior… A week or so of Googling for answers, and (in the end, almost random) fiddling with the configuration files, file permissions, etc etc, got me nowhere, so I decided to just live with it for a while.
Fast forward to Saturday night. I have no idea why I decided to mess with things again, but in the end I got so frustrated that I just completely uninstalled both the Apache server and PHP, and did a clean reinstall of them both, just before bedtime… Actually the reinstall went reasonably smoothly, to my considerable surprise. I broke a few other things along the way, PHPMyAdmin among them, but the server was up and running, correctly — after making those configuration changes that refused to work before — before I went to bed.
Yesterday I spent a little time fixing and rebuilding, and today I got the last error messages in PHPMyAdmin to go away. Anne was joking that I love a challenge, but playing with PHP would have been the challenge, and this was more like finding my bike tools needing repair (and in the end, replacement) before I could even work on the bike, to get ready for a challenging ride.
Mixing metaphors: I feel like like I’ve been putting off dealing with a toothache, and am now kicking myself after the dentist visit, for putting it off so long.
Just thought I’d check in, and brag (I was pushing 200# in March)…
The Sporting Life: The bike training continues apace, by the way. I’ve seen some definite improvement, in strength mostly. Endurance, not so much, but it should be coming. I have started riding Lehigh and Sals again, and I even broke out the singlespeed last night for Jacobsburg. What I really need is long road rides, sigh.
Meantime, Anne and I also signed up for the Hersey Half Marathon in October. Her sister, and a bunch of her nieces and nephews are doing it too. I should — hopefully — be ready in time.
Reading: I just finished The Mathematician’s Shiva, by Stuart Rojstaczer. Very good book, an awesome, well-written and well-structured read, with a great story — by turns funny and heartbreaking — with a lot of interesting math and science tidbits thrown in. It’s the story told by a professor of his mother, a towering figure in the world of mathematics who passes away, and the chaos that descends on their family when all her former students, acolytes, and adversaries come to pay their respects. There are also many jumps back to her early life, her work in mathematics, family history and dynamics, and academic and international politics. Just a really good book.
RIP Joe Martin: I had a funeral of my own to go to recently. My cousin Joseph Martin passed away a few weeks ago. He’d been suffering for many years with Huntington’s Disease, and had been institutionalized and bedridden for probably the last fifteen, and now his struggle is over. So sad, he was one of my older cousins, just two years older than me, and was the one I studied, as a pre-teen and teenager, for what “cool” was supposed to look like for me in a year or two.
The wake and funeral were both in his home town on Long Island, and many of his old friends and hockey teammates came, as well as a large portion of the Long Island side of my Dad’s extended family. The funeral home was just up the block from where Joe grew up — the last time I was there was 2002, for his mother’s funeral, and he was buried in the nearby cemetery with his mother. My cousin Wayne came up from Florida; he brought the ashes of his parents, and after Joe’s service we had a small ceremony at the cemetery, where they will be buried with their daughter, my cousin Suzanne who died at 19 in 1967. (We stood around and marveled at the massive trees that weren’t even there when she was buried.) A sad day, but one with a bit of closure, and it was good to see so many of my relatives, and hear so many stories…
GRAMPS, QGIS, Postgres: All that family talk, and all the photo albums that were bandied about, got me thinking about geneaology again, so I got that GRAMPS program up and running, and started updating what I had in there. I have about 250 people listed, but for many of them I don’t have much information other than where they fit in the family tree. Birth dates, death dates, where they lived or worked or got married, even for relatively close relatives I’m missing information. Working on it, along with everything else I’m fussing with.
It’ll be a whole other post, but I’ve also been playing with Geographic Information Systems using GRASS and QGIS (mostly QGIS), and that led me to start messing around with databases. I’d already installed and played with MySQL for a while, but even if it’s everywhere MySQL is not all that advanced (especially for GIS), and so I also got PostgrSQL/PostGIS up and running. I played with those for a bit, but sort of ran out of interest. Until…
I started thinking again about one of my pet peeves (lack of information about old family photos), and since I was hyped up about metadata after reading a book about it, I thought I should be able to do something to capture or store that information, especially electronically, when or if they got scanned. (I’m talking about who took the picture, when/where it was taken, who are the people in the photo, stuff like that.) Anyway, there are all sorts of methods, including embedded metadata in the image files (like EXIF data for digital photos, only these are XML-based and show different info); even GRAMPS could be used with a little work, but I finally decided on a Postgres database using LibreOffice Base to be the front end. I have been on a steep learning curve — mostly LibreOffice, and mostly YouTube tutorials with droning voice-overs, so I do it when Anne’s not around — ever since.
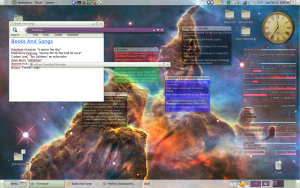
I’ve been playing a lot with the “eye candy” aspect of my computer setup lately. Not sure why, but I really got into the Compiz “window cube” decorations — I now have a whole bunch of medieval alchemy images hiding behind my ordinary screen (a close-up of the Crab Nebula), revealed when I spin the cube.
I also decided to put a bunch of screenlets, or desklets, or desk accessories, or whatever they’re calling them these days. I found the screenlets program and I really wasn’t all that impressed, but it led me to the program called Conky, which does pretty much the same thing, only much more impressively. The only problem is that Conky has an unwieldy, text based configuration, which in turn can call the Lua programming language to do fancy effects, and Lua in turn uses the Cairo graphics library. I had no idea any of these things existed…
So I spent some time learning something about these new languages, and now, besides the floating clock screenlet in the upper right, and a few screenlets for RSS feeds floating here and there, on the right side I have a simple conky reporting my laptop’s hardware stats. I don’t know if I need more than that, but may play with it some more just as a learning experience, and to candy-coat my screen some more.